Un boxplot, también conocido como diagrama de caja y bigotes, es una representación gráfica que permite visualizar la distribución y la dispersión de un conjunto de datos. Proporciona una visión general de la mediana, los cuartiles y los valores atípicos (outliers) de los datos.

Antes de entender un boxplot, es importante entender los conceptos de cuartiles y mediana:
- Mediana (Q2 / 50th Percentile): Es el valor que divide el conjunto de datos en dos partes iguales, de modo que la mitad de los valores son menores y la mitad son mayores.
- Cuartiles: Dividen los datos en cuatro partes iguales.
- Primer cuartil (Q1 / 25th Percentile): El 25% de los datos son menores que este valor.
- Tercer cuartil (Q3 / 75th Percentile): El 75% de los datos son menores que este valor.
- Rango intercuartílico (IQR): Es la distancia entre el primer y el tercer cuartil (Q3 – Q1).
- Valores Atípicos (Outliers): Son valores que se desvían significativamente del resto de los datos. Se suelen definir como aquellos valores que están por debajo de Q1 – 1.5 * IQR o por encima de Q3 + 1.5 * IQR.
El gráfico que ves en el boxplot a partir de un conjunto de datos aleatorios. Vamos a desglosar los componentes de este boxplot:

- Caja Central: El cuerpo de la caja del boxplot representa el rango intercuartílico (IQR), que es la distancia entre el primer y el tercer cuartil. En este caso, la caja contiene el 50% central de los datos.
- Línea dentro de la Caja: La línea que atraviesa la caja indica la mediana de los datos, el punto medio del conjunto de datos.
- Notch: La muesca alrededor de la mediana proporciona una visualización de la variabilidad de la mediana; si las muescas de dos boxplots no se superponen, esto sugiere que las medianas son significativamente diferentes.
- Bigotes: Los extremos de los bigotes representan el valor máximo y mínimo dentro del rango aceptable, que se calcula como 1.5 veces el IQR desde el primer y tercer cuartil. En este gráfico, los bigotes se extienden hasta el punto más alto y más bajo que no se considera un valor atípico.
- Puntos Externos: Los puntos que caen fuera de los bigotes son los valores atípicos o outliers. Estos son los valores que difieren significativamente de la mayoría de los datos y podrían ser indicativos de una variabilidad especial o errores de medición.
Para entender cómo se distribuyen estos datos, los hemos ordenado y calculado los cuartiles, así como la mediana:
- El primer cuartil (Q1) es 22, lo que significa que el 25% de los datos son menores o iguales a 22.
- La mediana (Q2) es 50, lo que indica que la mitad de los datos son menores o iguales a 50 y la otra mitad son mayores.
- El tercer cuartil (Q3) es aproximadamente 79.25, por lo que el 75% de los datos son menores o iguales a 79.25.
Ahora, vamos a presentar los datos ordenados visualmente para mostrar la mediana y los cuartiles con marcas. Esto ayudará a visualizar cómo los datos se agrupan alrededor de estos puntos estadísticos importantes.
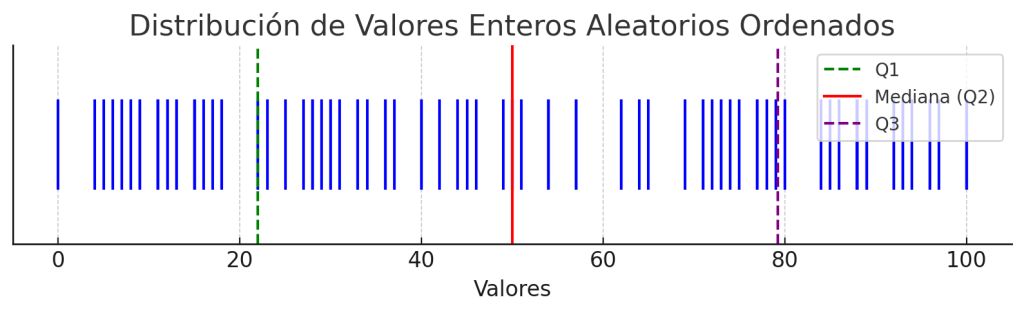
La visualización que ves arriba es un gráfico de los 100 valores enteros aleatorios que hemos generado, dispuestos en orden ascendente. Las líneas verticales representan:
- Línea Verde: Primer cuartil (Q1), donde el 25% de los datos son menores o iguales a este valor.
- Línea Roja: Mediana (Q2), que divide el conjunto de datos por la mitad.
- Línea Morada: Tercer cuartil (Q3), donde el 75% de los datos son menores o iguales a este valor.
La disposición de las marcas azules representa la distribución de los valores individuales. Puedes ver cómo los datos se agrupan más densamente alrededor de la mediana, y cómo se dispersan hacia los extremos, lo cual es típico en una distribución normal. Este gráfico de eventos proporciona una forma sencilla de visualizar dónde se concentran los datos y cómo se comparan con los puntos estadísticos clave como la mediana y los cuartiles.
Un ejemplo práctico
Vamos a simular el análisis de las alertas en la gestión de servidores web basados en LAMP (Linux, Apache, MySQL, PHP) En un entorno de operaciones el tiempo de resolución de alertas es un indicador clave de rendimiento (KPI). Para simular datos que reflejen esta situación, vamos a generar un conjunto de datos aleatorios siguiendo un patrón determinado.

El boxplot que se muestra representa el tiempo de resolución de alertas en minutos para un servicio de operaciones. Si fueras el responsable de operaciones, aquí hay algunos puntos clave que puedes deducir del gráfico y las estadísticas descriptivas:
- Mínimo (Min): La alerta más rápida se resolvió en aproximadamente 1.34 minutos, lo cual es excelente y sugiere que algunos sistemas o protocolos están funcionando muy eficientemente.
- Primer Cuartil (Q1): El 25% de las alertas se resolvieron en 5.02 minutos o menos. Esto indica que una cuarta parte de las alertas se manejan bastante rápido.
- Mediana: La mediana del tiempo de resolución es de aproximadamente 7.97 minutos. Esto significa que la mitad de las alertas se cierran en menos de 8 minutos, lo cual es un buen rendimiento. Sin embargo, esta cifra también indica que la otra mitad de las alertas toma más tiempo, lo cual es un área de posible mejora.
- Tercer Cuartil (Q3): El 75% de las alertas se resuelven en aproximadamente 12.65 minutos. Aquí se puede observar que el tiempo de resolución comienza a aumentar, lo que podría indicar casos más complejos o problemas en la eficiencia.
- Máximo (Max): Algunas alertas toman hasta 53.20 minutos para resolverse, lo que es significativamente más alto que la mayoría de los otros tiempos de resolución. Estos son casos atípicos y deben investigarse para entender las causas de tales retrasos.
- Media (Mean): El tiempo medio de resolución es de 10.65 minutos, lo cual está influenciado por los valores extremos en la cola derecha de la distribución.
- Desviación Estándar (Std Dev): Una desviación estándar de 9.63 minutos muestra una variabilidad considerable en el tiempo de resolución de las alertas.
Continuando con la simulación en un entorno operativo que gestiona alertas en una plataforma LAMP (Linux, Apache, MySQL, PHP), podemos clasificar las alertas resueltas en diferentes categorías basadas en su complejidad y el tiempo de resolución:
- Resoluciones Rápidas (< 5 minutos): Estas alertas pueden incluir problemas como reinicios de servicios, errores temporales de red que se resuelven automáticamente o pequeños cambios de configuración. Estos casos son generalmente rutinarios y pueden ser manejados rápidamente por el primer nivel de soporte.
- Resoluciones Moderadas (5-15 minutos): Este grupo podría estar compuesto por problemas como la degradación del rendimiento de la base de datos, errores de scripts PHP o problemas de autenticación. Estos problemas son más complejos y pueden requerir la intervención de un técnico más experimentado, pero aún se resuelven en un tiempo razonable.
- Resoluciones Lentas (> 15 minutos, < 30 minutos): Aquí podríamos tener problemas como la configuración errónea de un servidor virtual en Apache, la resolución de dependencias en aplicaciones PHP o la optimización de consultas en MySQL. Estos casos pueden necesitar una investigación detallada y un enfoque sistemático para resolverlos.
- Resoluciones Complejas (> 30 minutos): Estas alertas son las más críticas y podrían ser causadas por fallos graves del sistema, como un servidor Linux que se cuelga, un fallo del sistema de archivos o problemas de corrupción de datos en MySQL. Estas situaciones podrían requerir una respuesta de emergencia, posiblemente con múltiples miembros del equipo trabajando juntos, y podrían incluir la participación de desarrolladores, DBAs y administradores de sistemas.
Con esta clasificación y el boxplot puedes clasificar la cantidad de alertas y la velocidad de resolución que ha tenido el servicio de resolución de alertas.









 la media de la muestra
la media de la muestra ) .
) . y desviación estándar
y desviación estándar  de la diferencia de los valores.
de la diferencia de los valores. de experiencia por término medio. Decide poner a prueba su hipótesis nula de que la media de años de experiencia es de cinco años y su hipótesis alternativa de que la verdadera media de años de experiencia es inferior a cinco años, utilizando una muestra de 25 profesores.
de experiencia por término medio. Decide poner a prueba su hipótesis nula de que la media de años de experiencia es de cinco años y su hipótesis alternativa de que la verdadera media de años de experiencia es inferior a cinco años, utilizando una muestra de 25 profesores. 




![\[t = \frac{\overline{x}-\mu_o}{\frac{S_x}{\sqrt{n}}}\]](https://www.mox.es/wp-content/ql-cache/quicklatex.com-83b86c42ed9310497026368bc9e85d8a_l3.png "Rendered by QuickLaTeX.com")
 , donde
, donde 
![\[t = \frac{4-5}{\frac{2}{\sqrt{25}}} = -2.5\]](https://www.mox.es/wp-content/ql-cache/quicklatex.com-06aed3aa83a1028b99cda07b51cf1921_l3.png "Rendered by QuickLaTeX.com")


 (un 95% de certeza), dado que
(un 95% de certeza), dado que y
y 




 y
y  (ambas probabilidades).
(ambas probabilidades). .
. global, podemos usar el de la muestra, pero entonces lo llamaremos Error Estandar (Standar Error).
global, podemos usar el de la muestra, pero entonces lo llamaremos Error Estandar (Standar Error).



 , por tanto si sabemos que queremos un CI de 99% con un margen de error inferior al 2% (por poner une ejemplo). Primero obtendremos la inversa de Z para 99,5% que es 2.576 aprox. A partir de aquí sabemos que:
, por tanto si sabemos que queremos un CI de 99% con un margen de error inferior al 2% (por poner une ejemplo). Primero obtendremos la inversa de Z para 99,5% que es 2.576 aprox. A partir de aquí sabemos que:




 y
y  .
. (puede ser 0.05, 0.10, etc…)
(puede ser 0.05, 0.10, etc…) =
= 
 rechazar
rechazar  no rechazar
no rechazar  reject Ho
reject Ho fail to reject Ho
fail to reject Ho


![\[\sigma_{\hat{P}_A - \hat{P}_B} = \sqrt{{\frac{\hat{P_C}(1-\hat{P_C})}{n_{A}}}+{\frac{\hat{P_C}(1-\hat{P_C})}{n_{B}}}}\]](https://www.mox.es/wp-content/ql-cache/quicklatex.com-9bd60fa0460acbc463b39f28701bef7c_l3.png "Rendered by QuickLaTeX.com")
 es el promedio de las sumas
es el promedio de las sumas  y
y  (sumar subtotales, dividir por suma de totales).
(sumar subtotales, dividir por suma de totales).