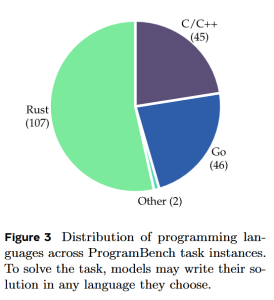
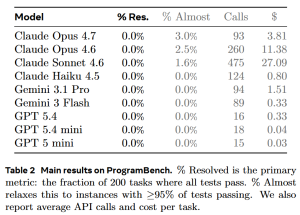
Rudraksha — from the Sanskrit «Rudra» (Lord Shiva) and «Aksha» (tears) — are among the most sacred seeds in Hindu and Buddhist tradition. Believed to be born from the tears of a god, each bead carries a different divine frequency. Here’s everything you need to know about these ancient spiritual tools, from mythology to market prices.

What Are Rudraksha?
Rudraksha are the seeds of the Elaeocarpus ganitrus tree, a tropical evergreen found primarily in Nepal (Arun Valley), Indonesia (Java and Sumatra), India, and parts of Southeast Asia. These trees grow at altitudes between 300 and 1,500 meters, producing blue outer fruits that enclose the wrinkled, brown seeds we know as Rudraksha beads.
Each seed naturally forms vertical grooves on its surface that converge at the top and bottom poles. The number of these grooves — called «mukhi» (faces) — determines the bead’s spiritual properties, associated deity, ruling planet, and even its market price.
Rudraksha have been used for thousands of years as prayer beads (mala), meditation aids, astrological remedies, and protective amulets. They appear in foundational Hindu scriptures including the Shiva Purana, Mahabharata, Rudraksha Jabala Upanishad, and multiple Tantras. In Buddhism, they’re equally revered, particularly in Tibetan and Nepalese Buddhist traditions.
Scientifically, Rudraksha seeds contain alkaloids, minerals, and trace elements (calcium, iron, magnesium, zinc, silicon) that have been studied for potential cardiovascular benefits — traditional Ayurvedic medicine uses them to regulate blood pressure and heart rate.
Origin Stories: Three Myths, One Seed
The Story of Shiva’s Penance (Most Popular)
According to the Shiva Purana, Lord Shiva — the great ascetic — meditated for thousands of years on Mount Kailash, completely withdrawn from the world, eyes closed in deep trance. When he finally opened them, he saw the immense suffering of humanity and was overwhelmed with compassion. Tears streamed down his face, and wherever they touched the earth, Rudraksha trees sprang up. The beads were thus born as Shiva’s gift of mercy to suffering mankind.
The Story of Tripurasur (The Demon of Three Cities)
A second version in the Shiva Purana tells of Tripurasur, a demon who had meditated for decades to please Lord Brahma and received a boon granting him three invincible cities. Tripurasur became consumed with pride and terrorized both gods and humans. Shiva, seeing the suffering, entered meditation to forge the deadly Aghor weapon to destroy the demon. When he emerged from meditation and opened his eyes, tears of compassion fell — from which Rudraksha trees grew, meant to protect humanity long after the demon was vanquished.
The Story of Shiva’s Sweat
A third variant says that during Shiva’s meditation on Mount Kailash, his intense spiritual energy caused drops of sweat to fall from his forehead. When these drops touched the ground, they transformed into seeds that grew into Rudraksha trees. This version emphasizes the beads’ connection to Shiva’s raw spiritual power rather than his compassion.
Adi Shankaracharya and the Discovery of Rudraksha
According to tradition, the great philosopher Adi Shankaracharya (8th century CE) was meditating near the Mandakini River when he saw a Rudraksha bead washed ashore. Recognizing its sacred nature, he began wearing Rudraksha malas and promoted their use among all castes and classes. The Rudraksha Jabala Upanishad — attributed to this era — explicitly states that Rudraksha should be worn by anyone regardless of social status: Brahmin, Kshatriya, Vaishya, or Shudra. This was radical at the time, when many spiritual practices were restricted by caste.
The 13 Faces: Deity, Planet, and Meaning
Each mukhi (face) is associated with a specific deity, ruling planet, sacred mantra, and set of benefits. Here’s a complete guide from 1 to 13 mukhi:
1 Mukhi — Lord Shiva ☀️ Sun
The most sacred and rare of all Rudraksha. The 1 Mukhi embodies the ultimate truth, unity, and pure consciousness. It’s considered the jewel among jewels — a single authentic round 1 Mukhi can cost up to $6,000.
Benefits: Enlightenment, moksha (liberation), enhanced concentration, detachment from worldly attachments, self-realization.
Mantra: Om Hreem Namaha
Note: A perfectly round 1 Mukhi with a single internal seed doesn’t exist in nature. Nepal produces oval/lentil-shaped 1 Mukhi that are considered authentic. Some «round» 1 Mukhi beads sold today are underdeveloped 4-5 mukhi beads with naturally formed single faces.
2 Mukhi — Shiva + Parvati 🌙 Moon
The Unity Bead. Represents the union of Shiva and Goddess Parvati (Ardhanarishvara), symbolizing duality in perfect harmony.
Benefits: Harmonious relationships — marriage, partnerships, family bonds. Emotional balance, love, compassion, conflict resolution.
Mantra: Om Namaha
3 Mukhi — Agni (Fire God) ♂ Mars
The Purification Bead. Associated with Agni, the divine fire that burns away impurities.
Benefits: Destroys past-life karma and sins. Eliminates inferiority complexes, fear, self-hatred, and mental stress. Boosts energy and eliminates laziness. Spiritual rebirth.
Mantra: Om Kleem Namaha
4 Mukhi — Lord Brahma ☿ Mercury
The Knowledge Bead. Brahma is the Creator of the universe and the bestower of knowledge and creativity.
Benefits: Enhanced memory, concentration, learning ability, and eloquence. Particularly beneficial for students and scholars. Improves speech and communication.
Mantra: Om Hreem Namaha
5 Mukhi — Kalagni Rudra (Shiva) ♃ Jupiter
The most common Rudraksha — over 90% of all beads are 5 Mukhi. Associated with Kalagni Rudra, a fierce form of Shiva. Known as the «Dev Guru Rudraksha» (Teacher of the Gods) because Jupiter is the guru of all deities.
Benefits: Destroys bad karma of the present life. Brings mental peace, health, protection from accidental death. Grants fame and renown. Essential for any meditation or sadhana practice.
Mantra: Om Hreem Namaha
6 Mukhi — Lord Kartikeya ♀ Venus
The Willpower Bead. Kartikeya is Shiva’s son and the commander of the celestial army.
Benefits: Courage, wisdom, willpower, and expressive power. Ideal for leaders, speakers, and performers. Also blessed by Parvati, Lakshmi, and Saraswati.
Mantra: Om Hreem Hum Namaha
7 Mukhi — Gauri (Lakshmi/Parvati) 🌙 Moon
The Charisma Bead. Gauri is the goddess of magnetic personality and abundance.
Benefits: Personal magnetism, love, prosperity, stress relief. Attracts positive energies and good fortune.
Mantra: Om Hum Namaha
8 Mukhi — Lord Kubera ♃ Jupiter / ♀ Venus
The Wealth Bead. Kubera is the god of wealth and treasure.
Benefits: Material prosperity, wisdom, removal of financial obstacles, power, and authority.
Mantra: Om Hum Namaha
9 Mukhi — Goddess Durga ♂ Mars
The Protection Bead. Durga is the warrior goddess, divine shield against all harm.
Benefits: Spiritual power, courage, protection against enemies and curses. Neutralizes negative astrological effects of Mars.
Mantra: Om Hreem Hum Namaha
10 Mukhi — Lord Vishnu ♄ Saturn
The Preservation Bead. Vishnu is the Preserver of the universe, associated with his ten incarnations (Dashavatara).
Benefits: Physical and mental health, leadership qualities, balance, relief from Saturn-related afflictions.
Mantra: Om Namaha
11 Mukhi — Lord Hanuman ⚡ No fixed planet
The Courage Bead. Hanuman is the god of bravery, strength, and adventure. This is the 11th of the 11 Rudras (forms of Shiva).
Benefits: Physical and mental courage, strength, confidence, elimination of cowardice. Spiritual protection.
Mantra: Om Hreem Hoom Namaha
12 Mukhi — Lord Surya (Sun) ☀️ Sun
The Leadership Bead. Surya, the sun god, creates a powerful aura around the wearer.
Benefits: Charisma, leadership, creativity, mental clarity, confidence. Also associated with relief from heart problems.
Mantra: Om Hreem Namaha
13 Mukhi — Indra + Kamadeva ♀ Venus / 🌙 Moon
The Love and Emotion Bead. Represents Indra (king of the gods) and Kamadeva (god of love and desire).
Benefits: Emotional control, love, attraction, magnetism. Mitigates negative effects of Venus and Moon in astrological charts. Considered rare and powerful.
Mantra: Om Hreem Namaha
Price Guide: How Much Do Rudraksha Cost?
Rudraksha prices vary dramatically based on mukhi count, origin, size, and quality. Nepal Arun Valley beads command 2-5x the price of Indonesian ones due to larger size (15-25mm vs. 8-15mm), deeper mukhi lines, and traditional preference.
| Mukhi |
Price Range (USD) |
Rarity |
| 1 Mukhi |
$30 – $6,000+ |
Extremely rare |
| 2 Mukhi |
$10 – $65 |
Very rare |
| 3 Mukhi |
$8 – $40 |
Rare |
| 4 Mukhi |
$6 – $30 |
Rare |
| 5 Mukhi |
$1 – $20 |
Very common |
| 6 Mukhi |
$6 – $30 |
Common |
| 7 Mukhi |
$9 – $45 |
Uncommon |
| 8 Mukhi |
$25 – $100 |
Uncommon |
| 9 Mukhi |
$40 – $150 |
Rare |
| 10 Mukhi |
$50 – $200 |
Rare |
| 11 Mukhi |
$60 – $250 |
Rare |
| 12 Mukhi |
$75 – $300 |
Very rare |
| 13 Mukhi |
$100 – $450 |
Very rare |
Key factors that affect price:
– Size: Larger beads (25mm+) can be 3-5x more expensive than standard sizes
– Origin: Nepal > Indonesia for price and traditional preference
– Shape: Round/oval beats irregular
– Clarity: Deep, well-defined mukhi lines add value
– Certification: Lab-certified beads (X-ray tested for internal seeds) cost more
Extreme cases: A Siddha Mala (one bead each of 1-14 mukhi combined) can cost $1,000–$15,000 depending on origin and quality. The legendary Brahma Mala (21 beads of 1 mukhi each) has been known to fetch $20,000+ at auctions.
Nepal vs. Indonesia: Which Should You Choose?
| Feature |
Nepal (Arun Valley) |
Indonesia (Java/Sumatra) |
| Size |
15-25mm (larger) |
8-15mm (smaller) |
| Mukhi lines |
Deep, clearly defined |
Shallower, less distinct |
| Texture |
Rough, thorny |
Smoother |
| Production |
Limited, seasonal |
Abundant |
| Best for |
Single beads, wearing, astrology |
Malas (108 beads), meditation |
| Price |
Premium (2-5x higher) |
More affordable |
| Fake risk |
Lower |
Higher (mass-produced fakes exist) |
How to Spot Fake Rudraksha
The market is flooded with counterfeit beads. Here’s how to identify real ones:
1. The water test: Real Rudraksha sinks immediately in water. Fakes (often made of resin or carved stone) float.
2. The nail test: Press a nail into the surface — real Rudraksha feels soft and slightly fibrous, like dried wood.
3. The mukhi lines: Genuine lines run continuously from top to bottom pole. Fakes often have lines that stop or merge.
4. The sound: Shake a mala — real Rudraksha make a soft, dull sound. Hard counterfeits clink like stone.
5. X-ray certification: For expensive beads (1, 2, 13+ mukhi), request lab certification that shows the internal seed structure matches the external mukhi count.
Final Thoughts
Rudraksha are more than pretty prayer beads — they’re one of the oldest continuously used spiritual tools in human history, with a documented presence in Hindu texts for over 3,000 years. Whether you’re drawn to them for meditation, astrological remedies, protection, or simply their organic beauty, there’s a mukhi for almost every intention.
The 5 Mukhi remains the most practical entry point: affordable, abundant, and powerful. But if you’re searching for something specific — Hanuman’s courage (11 Mukhi), Brahma’s knowledge (4 Mukhi), or Shiva’s ultimate realization (1 Mukhi) — the entire spectrum is available, provided you buy from reputable sources.
Just remember what the Shiva Purana says: «Even a person who has committed the most grievous sins can be purified by wearing Rudraksha with devotion.»
The only question is which face of Rudraksha resonates with yours.
Sources:
– Shiva Purana (Hindu scripture on Rudraksha origin)
– Rudraksha Jabala Upanishad (Vedic text on Rudraksha usage)
– Wikipedia — «Rudraksha»: https://en.wikipedia.org/wiki/Rudraksha
– Himalayas Shop — «Meaning of Different Rudraksha Mukhi»: https://www.himalayasshop.com/blogs/guides/meaning-of-different-rudraksha-mukhi
– IGL Delhi — «Rudraksha Types & Benefits»: https://igldelhi.com/pdf/rudraksha-benefits-and-uses.pdf
– Ratna Gems — «Nepal Rudraksha Price Guide 2026»: https://ratnagems.com/original-rudraksha-buying-guide/
– Rudraksha Ratna — «Legends of Rudraksha»: https://www.rudraksha-ratna.com/articles/legend-of-rudraksha
– Divine Hindu — «Rudraksha Origin Story»: https://www.divinehindu.in/blogs/news/rudraksha-origin-story