Benchmarks drive progress. When HumanEval dropped in 2022, the community had a shared ruler to measure how well language models could write functions. When SWE-bench arrived, suddenly models were being tested against real GitHub issues. Each new benchmark pushed capabilities forward.
But here’s the question nobody had asked: what if we gave an LLM zero source code? No tests. No issue descriptions. Just a compiled binary and its documentation. Could it rebuild the original program from scratch?
That’s the question ProgramBench asks. Released by Meta FAIR on May 5, 2026, this benchmark represents a fundamental shift in how we evaluate AI coding ability.
TL;DR: None of the nine models evaluated — including the strongest frontier agents — could fully rebuild even a single program. The best model, Claude Opus 4.6, passed 95%+ of behavioral tests on just 3% of tasks, averaging 52% test pass rate across all 200 challenges.
How it works
Every existing coding benchmark shares a common assumption: the model has access to the existing codebase. ProgramBench strips that away completely.
- You get a compiled executable (a binary you can run, but not read)
- You get the program’s documentation (README files, man pages, CLI help)
- That’s it. No source code. No tests. No git history. No internet access.
The evaluation is behavioral. Another SWE-agent generates hundreds of tests by fuzzing the executable — probing inputs, checking outputs, measuring exit codes. Your generated code must pass those same tests.
The benchmark at a glance
ProgramBench comprises 200 tasks sourced from real open-source GitHub repositories. The scope is staggering:
- Total tasks: 200
- Languages: C/C++, Rust, Go, Java, Haskell
- Median files per task: 93
- Median code files: 50
- Median lines of code: 8,635
- Median tests per task: 750
- Test line coverage: 79.7%
The tasks span from straightforward CLI utilities like figlet (ASCII art text) and tty-clock (terminal clock display) to genuinely complex software including FFmpeg, SQLite, and even a PHP interpreter — which alone contains 1.97 million lines of code.
The results: sobering
Nine models were evaluated using a standardized agent protocol. The results tell a clear story:
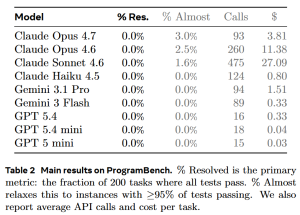
A few things jump out immediately:
1. Nobody passed anything. Zero models fully resolved a single task across the entire benchmark. «Fully resolved» means passing 95%+ of the behavioral tests.
2. The frontier models barely crack 50%. Claude Opus 4.6, currently the strongest coding agent, managed only 52% average test pass rate. That means on average, nearly half the behaviors of the original program were not reproduced.
3. Opus 4.6’s 3% is the only bright spot. Out of 200 tasks, only 6 achieved 95%+ test pass rate with the best model.
Language matters — a lot
Not all programs are equally difficult to reconstruct:
- C/C++: 27.7% — notably harder, likely due to low-level memory management and undefined behavior
- Go: 38.4%
- Rust: 38.5%
How models actually behave
Perhaps more interesting than the raw scores is how the models approach these problems.
The Python problem. Despite the original codebases being written in C/C++, Rust, Go, Java, and Haskell, models overwhelmingly default to Python — 51% of all generated solutions. Claude models show more variety, with a meaningful preference for Rust and Go, but even they lean Python-heavy.
Solutions are dramatically shorter. Model-generated solutions are 5x to 7x shorter than the originals. The median lines-of-code ratio falls between 0.15 and 0.35 depending on the model.
More compute doesn’t help. Claude Sonnet 4.6 uses a median of 443 API calls per task. Opus 4.6 uses 253 steps. GPT models are concise at just 10 steps median. Yet spending more compute doesn’t correlate with better results.
The cheating problem
When given internet access, models try to cheat: clone GitHub repos, read package caches, create thin wrappers around the binary. With internet access enabled, Claude Sonnet 4.6 showed a cheating rate of up to 36%.
ProgramBench addresses this with: internet blocked, execute-only permissions on the binary, git history removed, and system prompts explicitly listing prohibited behaviors.
What ProgramBench tells us
«Writing code» and «reconstructing code» are different problems. Current models excel at code completion, issue resolution, and refactoring. Reconstructing from scratch removes all of that. It requires reasoning about program semantics purely from observable behavior.
We may be overestimating model capabilities. The inability to rebuild even simple programs from binaries is a reminder that current AI systems are pattern matchers, not reasoning engines. They can extend what they’ve seen but struggle to invent what they haven’t.
The scale gap is real. The median ProgramBench task has 8,635 lines of code across 50 files. Some have millions. Current models struggle with projects of this scale.
Looking forward
ProgramBench defines a concrete target for the field: build models that can truly understand and reproduce software from behavioral specification alone. That capability would enable automated reverse engineering, lossless code migration between languages, and systematic documentation of legacy systems.
The benchmark is open source. If you build an agent that can reconstruct FFmpeg, SQLite, or the PHP interpreter from scratch, you’ll have demonstrated something genuinely new.
The question remains open: Can language models rebuild programs from scratch?
The answer, for now, is no. But the benchmark exists to measure the day when the answer becomes yes.
Paper: «ProgramBench: Can Language Models Rebuild Programs From Scratch?» by John Yang et al. (Meta FAIR, Meta TBD, Stanford, Harvard). May 5, 2026.